![]()
Packing for AWS Batch EC2 💼
When it comes to optimizing AWS Batch EC2 resources, diving into the intricate technicalities might seem daunting. However, my experiences have led me to uncover some practical insights and considerations that can significantly impact both performance and costs. Here’s a breakdown of ‘packing for Batch EC2’ strategies I’ve found useful:
When considering the following principles, you might find the ec2-instance-selector and/or my blog post on visual EC2 instance selection useful tools.
These principles apply not only when using AWS Batch natively, but also via workflow managers such as Nextflow.
Harnessing appropriate vCPU Sizes 🧮
Understanding vCPU counts and their increments is pivotal. CPU silicon is square in shape, and therefore, in most cases, CPU core counts go up in 2s. While there are exceptions, particularly for large/high core count server CPUs, they often increase in powers of 2 (i.e., 2, 4, 8, 16, 32, 64, 128, and so forth). Deviating from these increments will often result in over-provisioning, leading to underutilisation of available cores. While memory tends to play a crucial role in bioinformatics, reevaluating vCPU requirements can be equally beneficial and should not be overlooked.

For instance, suppose a job is parameterized to demand 6 vCPUs and 16 GiB of RAM. A swift check using the ec2-instance-selector reveals that AWS Batch might assign this job to an m7i-flex.2xlarge Spot instance, priced at $0.0962/Hr.
ec2-instance-selector --memory-min 16 --vcpus-min 6 --cpu-architecture x86_64 -r ap-southeast-2 -o table-wide --max-results 10 --usage-class spot --sort-by spot-priceHowever, tweaking the request to 4 vCPUs could downscale it to an m7i-flex.xlarge Spot instance, costing only $0.0484/Hr.
ec2-instance-selector --memory-min 16 --vcpus-min 4 --cpu-architecture x86_64 -r ap-southeast-2 -o table-wide --max-results 10 --usage-class spot --sort-by spot-priceEssentially, unless the job’s runtime is twice as slow with the 33% reduction in vCPUs, it’s more cost-efficient to scale back.
Kawaklia et al. 2015 published performance statistics for the popular sequence aligner BWA-Mem, illustrating that the runtime halves each time the number of threads (vCPUs) are doubled. For the above example, it would be more cost-efficient to reduce the job parameters from 6 to 4 vCPUs. Alternatively, you could increase it to 8 vCPUs, where you will typically pay twice the hourly instance price, but the runtime would now be halved, essentially resulting in the same job cost as 4 vCPUs.
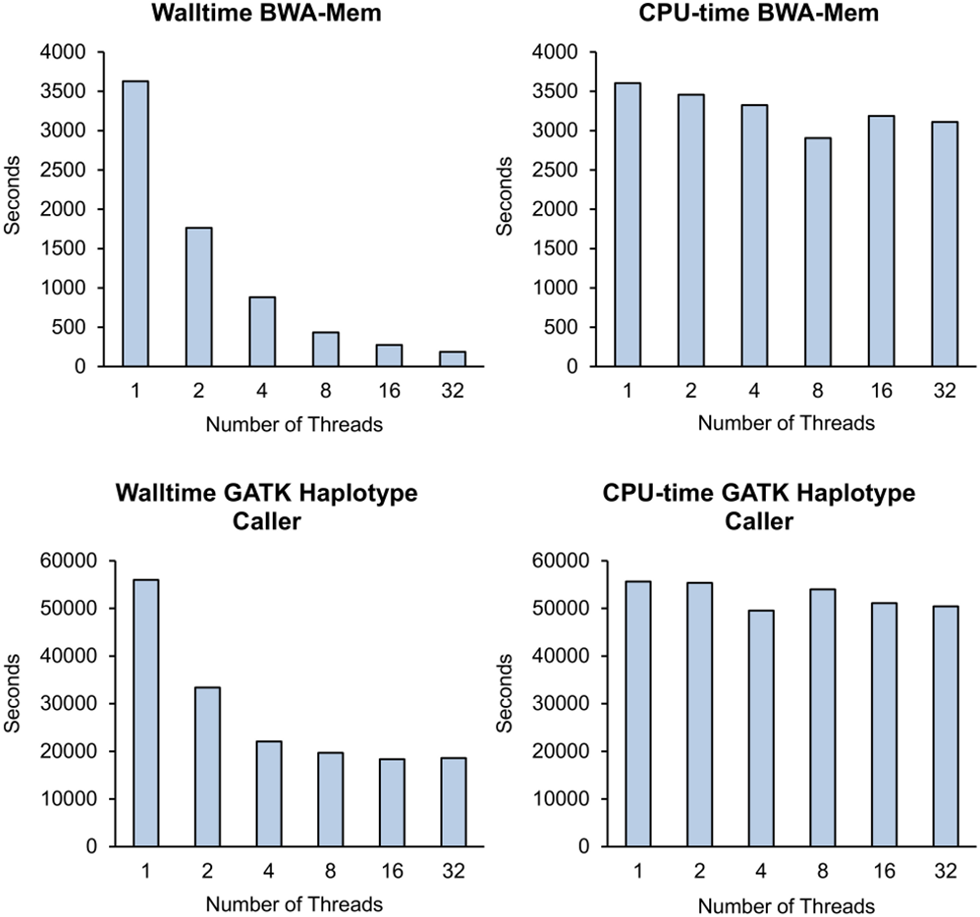
A lot of bioinformatics tools will refer to threads or cores, while cloud computing talks in vCPUs. Threads and cores are physical processing units, while vCPUs are virtual processing units provisioned by the physical processors with the ability to run one processor thread. Typically each CPU cores will have 2 threads, and therefore the maximum vCPU count will be #Cores X2. Some servers are capable of running dual CPUs so this number could double again. In general terms when converting threads to vCPUs its a 1:1 conversion.
Sizing Memory Prudently 📏
In bioinformatics, memory requirements often steer resource allocation. Similar to vCPUs, memory increments follow powers of 2, such as 16, 32, 64GiB, and so forth. Aligning your job’s memory needs with these blocks will help ensure efficient utilisation of resources.
AWS Batch tends to favour allocating jobs to small or medium Spot instances (where possible), avoiding larger ones like 8xlarge or 16xlarge instances. This preference might stem from lower interruption frequencies and/or the wider availability of smaller instances. Ultimately it is all controlled by AWS’s SPOT_PRICE_CAPACITY_OPTIMIZED strategy, aiming for a fine balance between price and capacity.

All in all, I would recommend that you ignore 8xlarge and 16xlarge instances when calculating how jobs may get packed into an instance.
When running AWS Batch with on-demand instances, rather than Spot, you often find AWS jams your jobs into much larger instances, however the following is still good practise and will still be beneficial.
While it is theoretically possible that 5 individual jobs requesting 36GiB each could be grouped together onto a single instance with 192GiB of RAM (93.75% utilisation), it is more likely that they will be placed on separate individual instances, each with 64 GiB RAM (56.25% utilisation). This would not be ideal for your budget 💸 What would likely be better is if you requested 32 GiB RAM; then, they could run on single 32GiB instances or be grouped in multiples on 64GiB or 96GiB instances without wasting RAM allocations. More often than not, delivering better bang for your buck 💵

It’s wise to plan job requests around small or medium instance sizes rather than assuming AWS Batch will fit them neatly into larger instances.
Runtime ⏱️
Although not immediately related to ‘EC2 packing,’ optimizing the runtime of your Batch spot instances can make a significant improvement in your cost efficiency.
While there is the well-known concept that the longer your Spot instance runs, the more likely it is to be interrupted, there is also a sometimes lesser-known fact. If a spot instance is interrupted/reclaimed by AWS within the first hour of running, you do not incur any fees 🤯 Yes, that means as long as your job runtimes are less than 1 hour, you essentially get free 🆓 retries (excluding other costs such as EBS).

For jobs that run for extended periods, there could be justification to submit these to an on-demand Batch compute environment to avoid potentially expensive retry costs.
Review Review Review 🔍
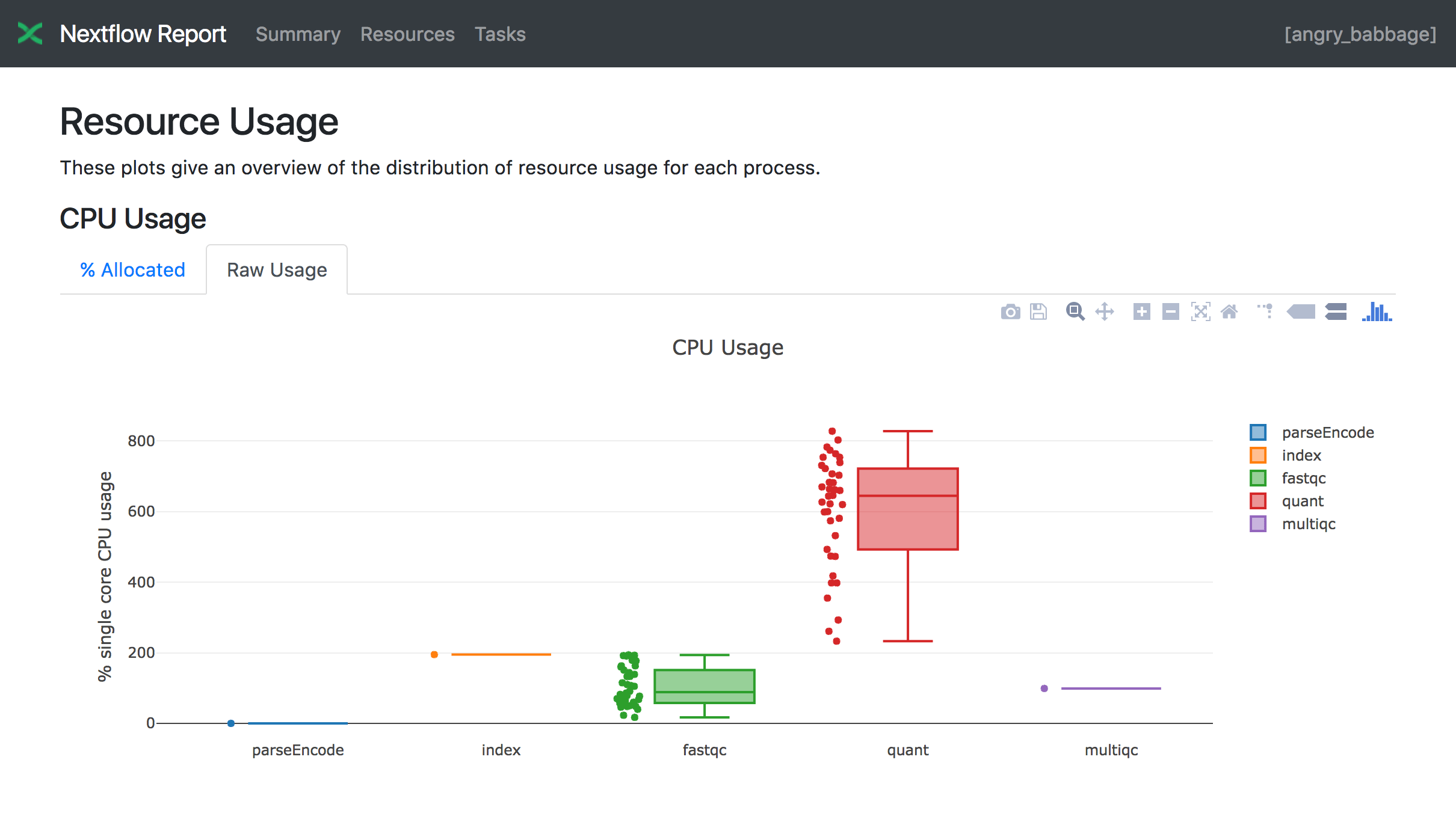
Optimization is a progressive process. You need to review your Batch jobs to determine how much RAM and vCPUs are actually being utilized for your data input types and which type of instances in your region AWS likes to provision. Using a workflow manager like Nextflow that reports on the actual resource usage of individual jobs is a great way to interrogate and optimize a larger number of job types. Even better the Seqera platform for Nextflow will attempt to optimise your resource requests based on past run info.
‘Packing for AWS Batch EC2’ is more than just fitting jobs into instances; it’s about optimising performance and costs through savvy 😎 resource allocation.